本文共 13655 字,大约阅读时间需要 45 分钟。
LeNet
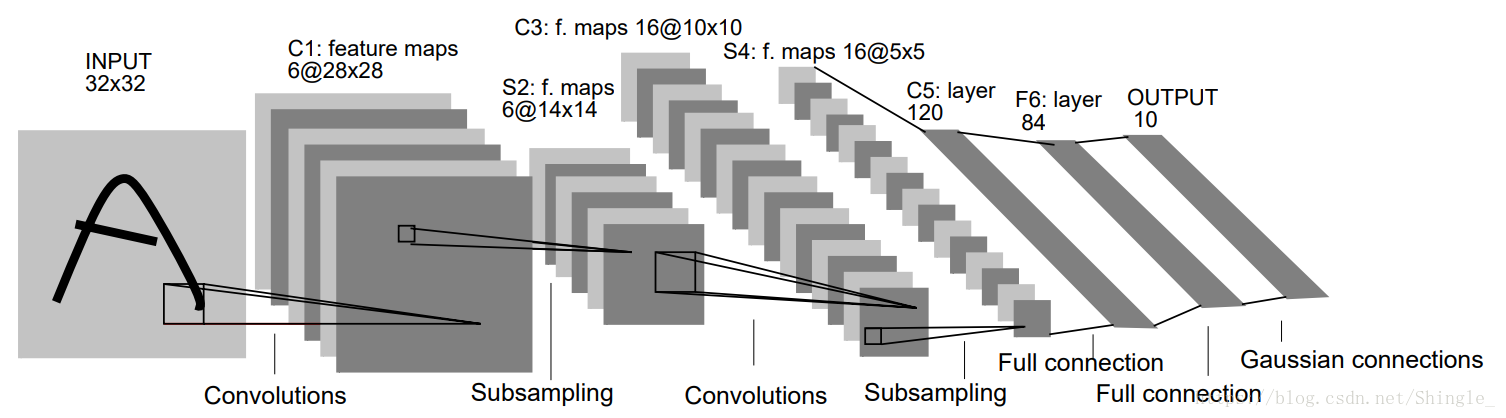
卷积神经网络
net = nn.Sequential()net.add( nn.Conv2D(channels=6, kernel_size=5, activation='sigmoid'), nn.MaxPool2D(pool_size=2, strides=2), nn.Conv2D(channels=16, kernel_size=5, activation='sigmoid'), nn.MaxPool2D(pool_size=2, strides=2), # Dense 会默认将(批量大小,通道,高,宽)形状的输入转换成 #(批量大小,通道 * 高 * 宽)形状的输入。 nn.Dense(120, activation='sigmoid'), nn.Dense(84, activation='sigmoid'), nn.Dense(10))
尝试基于 LeNet 构造更复杂的网络来改善精度。例如,调整卷积窗口大小、输出通道数、激活函数和全连接层输出个数。在优化方面,可以尝试使用不同的学习率、初始化方法以及增加迭代周期。
AlexNet
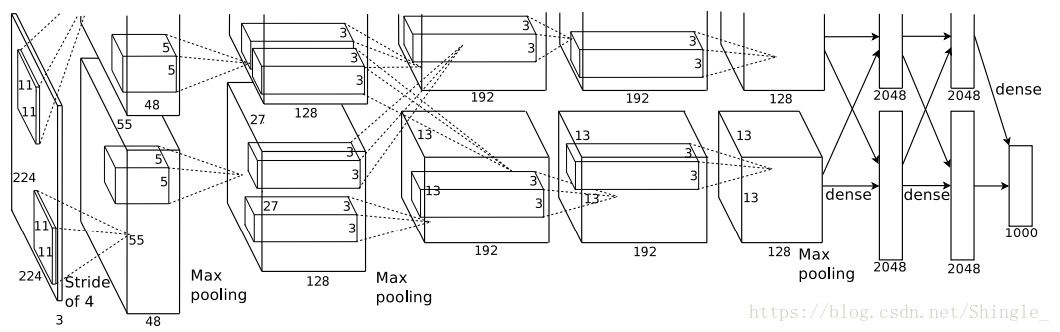
深度卷积神经网络
AlextNet 与 LeNet 的设计理念非常相似。但也有显著的区别。
- 第一,与相对较小的 LeNet 相比,AlexNet 包含 8 层变换,其中有五层卷积和两层全连接隐含层,以及一个全连接输出层。
第一层中的卷积窗口形状是 11×11。因为 ImageNet 中绝大多数图像的高和宽均比 MNIST 图像的高和宽大十倍以上,ImageNet 图像的物体占用更多的像素,所以需要更大的卷积窗口来捕获物体。第二层中的卷积窗口形状减小到 5×5,之后全采用 3×3。此外,第一、第二和第五个卷积层之后都使用了窗口形状为 3×3、步幅为 2 的最大池化层。而且,AlexNet 使用的卷积通道数也数十倍大于 LeNet 中的卷积通道数。
紧接着最后一个卷积层的是两个输出个数为 4096 的全连接层。这两个巨大的全连接层带来将近 1GB 的模型参数。由于早期 GPU 显存的限制,最早的 AlexNet 使用双数据流的设计使得一个 GPU 只需要处理一半模型。幸运的是 GPU 内存在过去几年得到了长足的发展,通常我们不再需要这样的特别设计了。
第二,AlextNet 将 sigmoid 激活函数改成了更加简单的 ReLU 激活函数。ReLU 激活函数的计算更简单,同时在不同的参数初始化方法下使模型更容易训练。
第三,通过丢弃法(参见“丢弃法”一节)来控制全连接层的模型复杂度。
第四,引入了大量的图像增广,例如翻转、裁剪和颜色变化,进一步扩大数据集来缓解过拟合。我们将在后面的“图像增广”一节详细介绍这些方法。
net = nn.Sequential()net.add( # 使用较大的 11 x 11 窗口来捕获物体。同时使用步幅 4 来较大减小输出高宽。 # 这里使用的输入通道数比 LeNet 也要大很多。 nn.Conv2D(96, kernel_size=11, strides=4, activation='relu'), nn.MaxPool2D(pool_size=3, strides=2), # 减小卷积窗口,使用填充为 2 来使得输入输出高宽一致,且增大输出通道数。 nn.Conv2D(256, kernel_size=5, padding=2, activation='relu'), nn.MaxPool2D(pool_size=3, strides=2), # 连续三个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。 # 前两个卷积层后不使用池化层来减小输入的高宽。 nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'), nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'), nn.Conv2D(256, kernel_size=3, padding=1, activation='relu'), nn.MaxPool2D(pool_size=3, strides=2), # 使用比 LeNet 输出个数大数倍的全连接层。使用丢弃层来控制复杂度。 nn.Dense(4096, activation="relu"), nn.Dropout(0.5), nn.Dense(4096, activation="relu"), nn.Dropout(0.5), # 输出层。我们这里使用 Fashion-MNIST,所以用类别数 10,而非论文中的 1000。 nn.Dense(10))
AlexNet 跟 LeNet 结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集 ImageNet。它是浅层神经网络和深度神经网络的分界线。虽然看上去 AlexNet 的实现比 LeNet 也就多了几行而已,但这个观念上的转变和真正优秀实验结果的产生,学术界为之整整花了 20 年
VGG
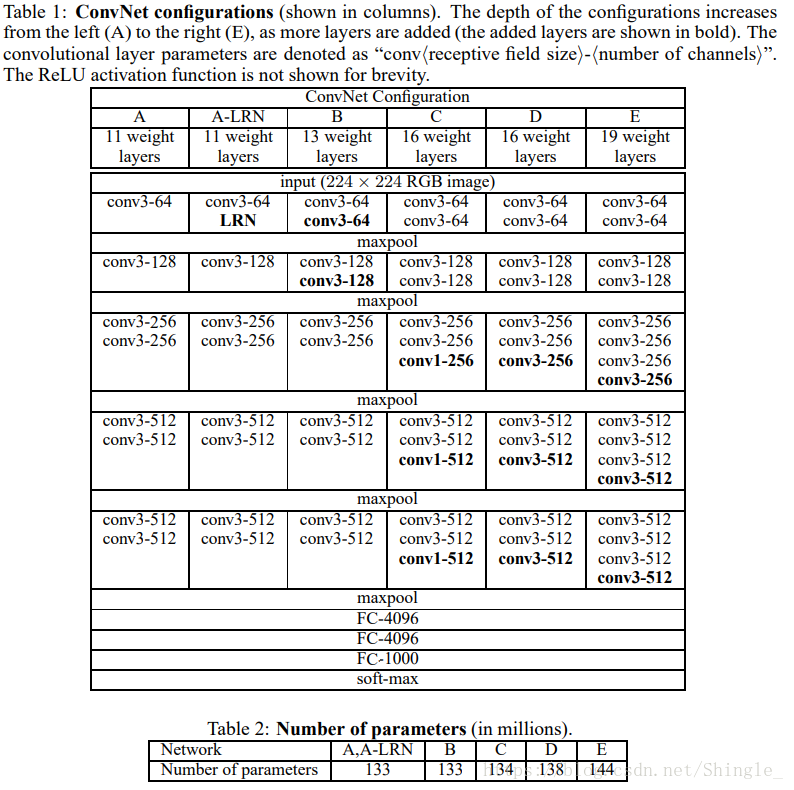
使用重复元素的网络
VGG 块
VGG 块的组成规律是:连续使用数个相同的填充为 1、窗口形状为 3×3 的卷积层后接上一个步幅为 2、窗口形状为 2×2 的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。我们使用vgg_block函数来实现这个基础的 VGG 块,它可以指定卷积层的数量num_convs和输出通道数num_channels。
def vgg_block(num_convs, num_channels): blk = nn.Sequential() for _ in range(num_convs): blk.add(nn.Conv2D( num_channels, kernel_size=3, padding=1, activation='relu')) blk.add(nn.MaxPool2D(pool_size=2, strides=2)) return blk
VGG 网络
VGG 网络同 AlexNet 和 LeNet 一样是由卷积层模块后接全连接层模块构成。卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个 VGG 块里卷积层个数和输出通道数。全连接模块则跟 AlexNet 中的一样。
现在我们构造一个 VGG 网络。它有 5 个卷积块,前两块使用单卷积层,而后三块使用双卷积层。第一块的输出通道是 64,之后每次对输出通道数翻倍,直到变为 512。因为这个网络使用了 8 个卷积层和 3 个全连接层,所以经常被称为 VGG-11。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))def vgg(conv_arch): net = nn.Sequential() # 卷积层部分。 for (num_convs, num_channels) in conv_arch: net.add(vgg_block(num_convs, num_channels)) # 全连接层部分。 net.add(nn.Dense(4096, activation='relu'), nn.Dropout(0.5), nn.Dense(4096, activation='relu'), nn.Dropout(0.5), nn.Dense(10)) return netnet = vgg(conv_arch)
NiN
即 1×1 卷积层
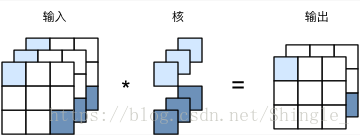
卷积窗口形状为 1×1(kh=kw=1)的多通道卷积层,我们通常称之为 1×1 卷积层,并将其中的卷积运算称为 1×1 卷积。因为使用了最小窗口,1×1 卷积失去了卷积层可以识别高宽维上相邻元素构成的模式的功能。实际上,1×1 卷积的主要计算发生在通道维上。值得注意的是,输入和输出的高宽相同。输出中的每个元素来自输入中在高和宽上相同位置的元素在不同通道之间的按权重累加。假设我们将通道维当做是特征维,将高和宽维度上的元素当成数据样本,那么 1×1 卷积层的作用与全连接层等价。
NiN 块
def nin_block(num_channels, kernel_size, strides, padding): blk = nn.Sequential() blk.add(nn.Conv2D(num_channels, kernel_size, strides, padding, activation='relu'), nn.Conv2D(num_channels, kernel_size=1, activation='relu'), nn.Conv2D(num_channels, kernel_size=1, activation='relu')) return blk
NiN 模型
NiN 是在 AlexNet 问世后不久提出的。它们的卷积层设定有类似之处。NiN 使用卷积窗口形状分别为 11×11、5×5 和 3×3 的卷积层,相应的输出通道数也与 AlexNet 中的一致。每个 NiN 块后接一个步幅为 2、窗口形状为 3×3 的最大池化层。
net = nn.Sequential()net.add( nin_block(96, kernel_size=11, strides=4, padding=0), nn.MaxPool2D(pool_size=3, strides=2), nin_block(256, kernel_size=5, strides=1, padding=2), nn.MaxPool2D(pool_size=3, strides=2), nin_block(384, kernel_size=3, strides=1, padding=1), nn.MaxPool2D(pool_size=3, strides=2), nn.Dropout(0.5), # 标签类别数是 10。 nin_block(10, kernel_size=3, strides=1, padding=1), # 全局平均池化层将窗口形状自动设置成输出的高和宽。 nn.GlobalAvgPool2D(), # 将四维的输出转成二维的输出,其形状为(批量大小,10)。 nn.Flatten())
GoogLeNet
GoogLeNet 吸收了 NiN 中网络嵌套网络的思想,并在此基础上做了很大改进。
Inception 块
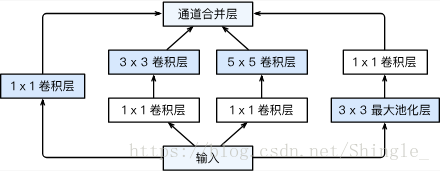
Inception 里有四个并行的线路。前三个线路里使用窗口大小分别是 1×1、3×3 和 5×5 的卷积层来抽取不同空间尺寸下的信息。其中中间两个线路会对输入先作用 1×1 卷积来减小输入通道数,以此降低模型复杂度。第四条线路则是使用 3×3 最大池化层,后接 1×1 卷积层来变换通道。四条线路都使用了合适的填充来使得输入输出高宽一致。最后我们将每条线路的输出在通道维上合并,输入到接下来的层中去。
Inception 块中可以自定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
class Inception(nn.Block): # c1 - c4 为每条线路里的层的输出通道数。 def __init__(self, c1, c2, c3, c4, **kwargs): super(Inception, self).__init__(**kwargs) # 线路 1,单 1 x 1 卷积层。 self.p1_1 = nn.Conv2D(c1, kernel_size=1, activation='relu') # 线路 2,1 x 1 卷积层后接 3 x 3 卷积层。 self.p2_1 = nn.Conv2D(c2[0], kernel_size=1, activation='relu') self.p2_2 = nn.Conv2D(c2[1], kernel_size=3, padding=1, activation='relu') # 线路 3,1 x 1 卷积层后接 5 x 5 卷积层。 self.p3_1 = nn.Conv2D(c3[0], kernel_size=1, activation='relu') self.p3_2 = nn.Conv2D(c3[1], kernel_size=5, padding=2, activation='relu') # 线路 4,3 x 3 最大池化层后接 1 x 1 卷积层。 self.p4_1 = nn.MaxPool2D(pool_size=3, strides=1, padding=1) self.p4_2 = nn.Conv2D(c4, kernel_size=1, activation='relu') def forward(self, x): p1 = self.p1_1(x) p2 = self.p2_2(self.p2_1(x)) p3 = self.p3_2(self.p3_1(x)) p4 = self.p4_2(self.p4_1(x)) # 在通道维上合并输出。 return nd.concat(p1, p2, p3, p4, dim=1)
GoogLeNet 模型
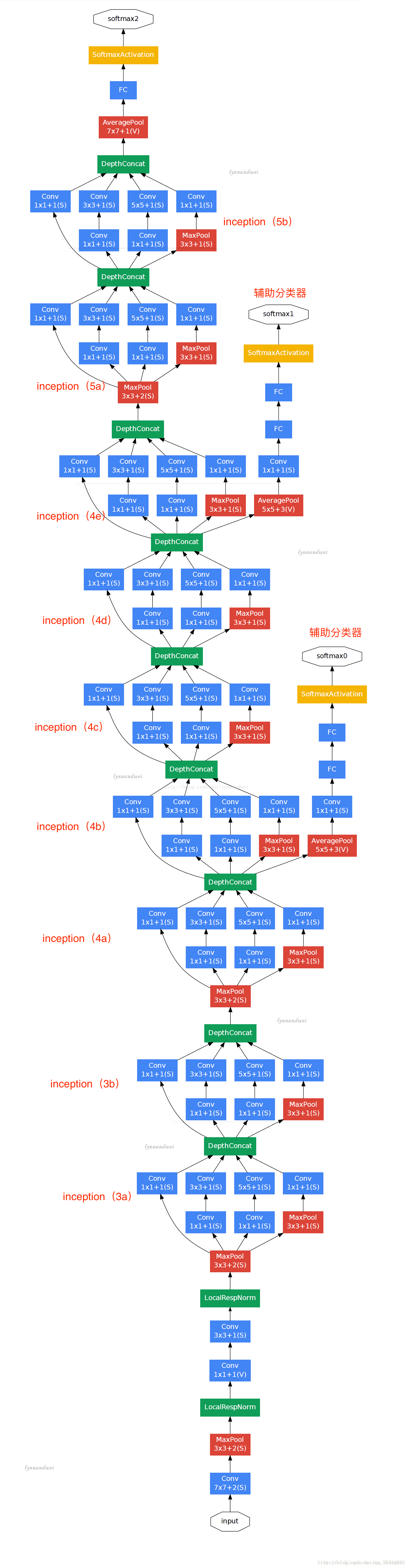
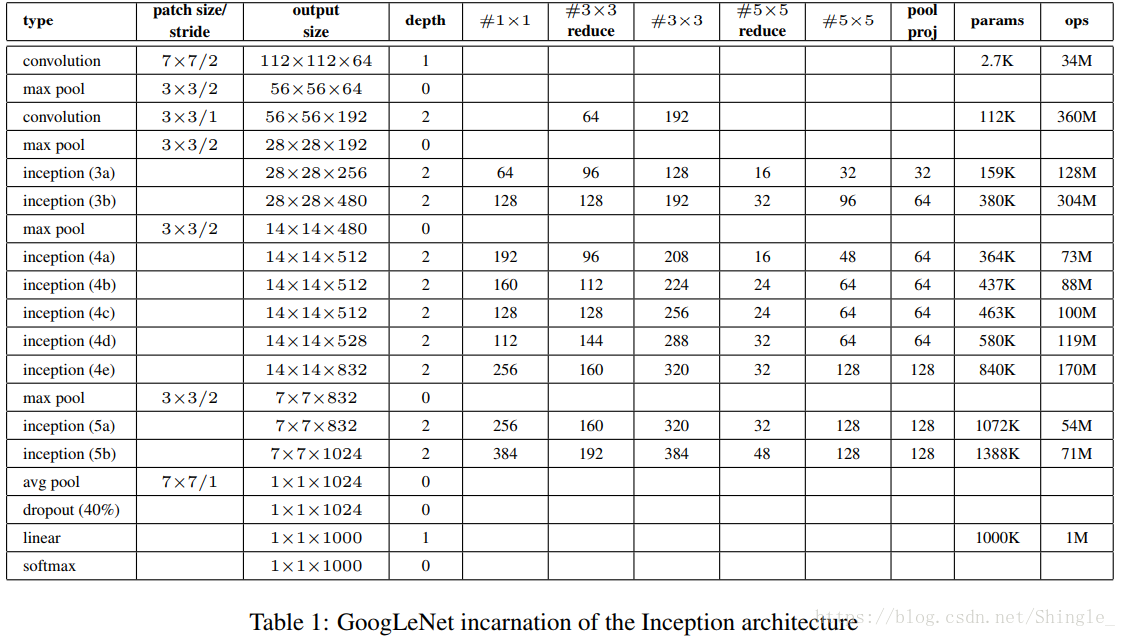
GoogLeNet 跟 VGG 一样,在主体卷积部分中使用五个模块,每个模块之间使用步幅为 2 的 3×3 最大池化层来减小输出高宽。第一模块使用一个 64 通道的 7×7 卷积层。
b1 = nn.Sequential()b1.add( nn.Conv2D(64, kernel_size=7, strides=2, padding=3, activation='relu'), nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第二模块使用两个卷积层,首先是 64 通道的 1×1 卷积层,然后是将通道增大 3 倍的 3×3 卷积层。它对应 Inception 块中的第二线路。
b2 = nn.Sequential()b2.add( nn.Conv2D(64, kernel_size=1), nn.Conv2D(192, kernel_size=3, padding=1), nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第三模块串联两个完整的 Inception 块。第一个 Inception 块的输出通道数为 256,其中四个线路的输出通道比例为 2:4:1:1。且第二、三线路先分别将输入通道减小 2 倍和 12 倍后再进入第二层卷积层。第二个 Inception 块输出通道数增至 480,每个线路的通道比例为 4:6:3:2。且第二、三线路先分别减少 2 倍和 8 倍通道数。
b3 = nn.Sequential()b3.add( Inception(64, (96, 128), (16, 32), 32), Inception(128, (128, 192), (32, 96), 64), nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第四模块更加复杂,它串联了五个 Inception 块,其输出通道分别是 512、512、512、528 和 832。其线路的通道分配类似之前,3×3 卷积层线路输出最多通道,其次是 1×1 卷积层线路,之后是 5×5 卷积层和 3×3 最大池化层线路。其中前两个线路都会先按比例减小通道数。这些比例在各个 Inception 块中都略有不同。
b4 = nn.Sequential()b4.add( Inception(192, (96, 208), (16, 48), 64), Inception(160, (112, 224), (24, 64), 64), Inception(128, (128, 256), (24, 64), 64), Inception(112, (144, 288), (32, 64), 64), Inception(256, (160, 320), (32, 128), 128), nn.MaxPool2D(pool_size=3, strides=2, padding=1))
第五模块有输出通道数为 832 和 1024 的两个 Inception 块,每个线路的通道分配使用同前的原则,但具体数字又是不同。因为这个模块后面紧跟输出层,所以它同 NiN 一样使用全局平均池化层来将每个通道高宽变成 1。最后我们将输出变成二维数组后加上一个输出大小为标签类数的全连接层作为输出。
b5 = nn.Sequential()b5.add( Inception(256, (160, 320), (32, 128), 128), Inception(384, (192, 384), (48, 128), 128), nn.GlobalAvgPool2D())net = nn.Sequential()net.add(b1, b2, b3, b4, b5, nn.Dense(10))
Inception 块相当于一个有四条线路的子网络,它通过不同窗口大小的卷积层和最大池化层来并行抽取信息,并使用 1×1 卷积层减低通道数来减少模型复杂度。GoogLeNet 将多个精细设计的 Inception 块和其他层串联起来。其通道分配比例是在 ImageNet 数据集上通过大量的实验得来。GoogLeNet 和它的后继者一度是 ImageNet 上最高效的模型之一,即在给定同样的测试精度下计算复杂度更低。
后续版本包括加入批量归一化层、对 Inception 块做调整 和加入残差连接。
ResNet
ResNet 成功地通过增加跨层的数据线路来允许梯度快速地到达底部层。
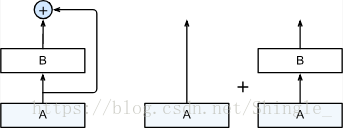
ResNet 沿用了 VGG 全 3×3 卷积层设计。残差块里首先是两个有同样输出通道的 3×3 卷积层,每个卷积层后跟一个批量归一化层和 ReLU 激活层。然后我们将输入跳过这两个卷积层后直接加在最后的 ReLU 激活层前。这样的设计要求两个卷积层的输出与输入形状一样,从而可以相加。如果想改变输出的通道数,我们需要引入一个额外的 1×1 卷积层来将输入变换成需要的形状后再相加。
class Residual(nn.Block): def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs): super(Residual, self).__init__(**kwargs) self.conv1 = nn.Conv2D(num_channels, kernel_size=3, padding=1, strides=strides) self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1) if use_1x1conv: self.conv3 = nn.Conv2D(num_channels, kernel_size=1, strides=strides) else: self.conv3 = None self.bn1 = nn.BatchNorm() self.bn2 = nn.BatchNorm() def forward(self, X): Y = nd.relu(self.bn1(self.conv1(X))) Y = self.bn2(self.conv2(Y)) if self.conv3: X = self.conv3(X) return nd.relu(Y + X)
ResNet 模型

ResNet 前面两层跟前面介绍的 GoogLeNet 一样,在输出通道为 64、步幅为 2 的 7×7 卷积层后接步幅为 2 的 3×3 的最大池化层。不同一点在于 ResNet 的每个卷积层后面增加的批量归一化层.
net = nn.Sequential()net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3), nn.BatchNorm(), nn.Activation('relu'), nn.MaxPool2D(pool_size=3, strides=2, padding=1)) GoogLeNet 在后面接了四个由 Inception 块组成的模块。ResNet 则是使用四个由残差块组成的模块,每个模块使用若干个同样输出通道的残差块。第一个模块的通道数同输入一致,同时因为之前已经使用了步幅为 2 的最大池化层,所以也不减小高宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并减半高宽。
def resnet_block(num_channels, num_residuals, first_block=False): blk = nn.Sequential() for i in range(num_residuals): if i == 0 and not first_block: blk.add(Residual(num_channels, use_1x1conv=True, strides=2)) else: blk.add(Residual(num_channels)) return blk
net.add(resnet_block(64, 2, first_block=True), resnet_block(128, 2), resnet_block(256, 2), resnet_block(512, 2))
这里每个模块里有 4 个卷积层(不计算 1×1 卷积层),加上最开始的卷积层和最后的全连接层,一共有 18 层。这个模型也通常被称之为 ResNet-18。通过配置不同的通道数和模块里的残差块数我们可以得到不同的 ResNet 模型。
残差块通过将输入加在卷积层作用过的输出上来引入跨层通道。这使得即使非常深的网络也能很容易训练。
DenseNet
ResNet 中的跨层连接设计引申出了数个后续工作。这一节我们介绍其中的一个:稠密连接网络(DenseNet)。 它与 ResNet 的主要区别如下:

主要区别在于,DenseNet 里层 B 的输出不是像 ResNet 那样和层 A 的输出相加,而是在通道维上合并,这样层 A 的输出可以不受影响的进入上面的神经层。这个设计里,层 A 直接跟上面的所有层连接在了一起,这也是它被称为“稠密连接“的原因。
DenseNet 的主要构建模块是稠密块和过渡块,前者定义了输入和输出是如何合并的,后者则用来控制通道数不要过大。
稠密块
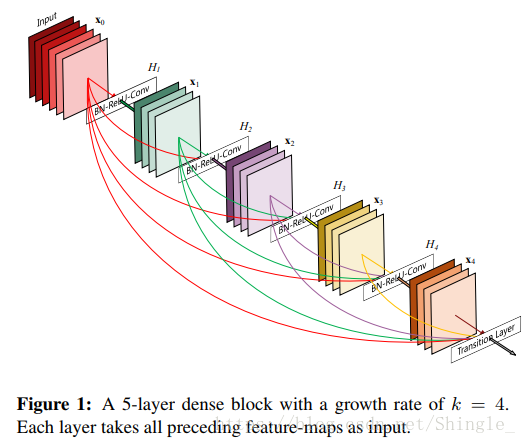
上图中growth rate即输出的chennal数。卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率(growth rate)。
DenseNet 使用了 ResNet 改良版的“批量归一化、激活和卷积”结构
def conv_block(num_channels): blk = nn.Sequential() blk.add(nn.BatchNorm(), nn.Activation('relu'), nn.Conv2D(num_channels, kernel_size=3, padding=1)) return blkclass DenseBlock(nn.Block): def __init__(self, num_convs, num_channels, **kwargs): super(DenseBlock, self).__init__(**kwargs) self.net = nn.Sequential() for _ in range(num_convs): self.net.add(conv_block(num_channels)) def forward(self, X): for blk in self.net: Y = blk(X) # 在通道维上将输入和输出合并。 X = nd.concat(X, Y, dim=1) return X 过渡块
由于每个稠密块都会带来通道数的增加。使用过多则会导致过于复杂的模型。过渡块(transition block)则用来控制模型复杂度。它通过 1×1 卷积层来减小通道数,同时使用步幅为 2 的平均池化层来将高宽减半来进一步降低复杂度。
def transition_block(num_channels): blk = nn.Sequential() blk.add(nn.BatchNorm(), nn.Activation('relu'), nn.Conv2D(num_channels, kernel_size=1), nn.AvgPool2D(pool_size=2, strides=2)) return blk DenseNet 模型

DenseNet 首先使用跟 ResNet 一样的单卷积层和最大池化层:
net = nn.Sequential()net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3), nn.BatchNorm(), nn.Activation('relu'), nn.MaxPool2D(pool_size=3, strides=2, padding=1)) 类似于 ResNet 接下来使用的四个基于残差块,DenseNet 使用的是四个稠密块。同 ResNet 一样我们可以设置每个稠密块使用多少个卷积层,这里我们设成 4,跟上一节的 ResNet 18 保持一致。稠密块里的卷积层通道数(既增长率)设成 32,所以每个稠密块将增加 128 通道。
ResNet 里通过步幅为 2 的残差块来在每个模块之间减小高宽,这里我们则是使用过渡块来减半高宽,并且减半输入通道数。
# 当前的数据通道数。num_channels = 64growth_rate = 32num_convs_in_dense_blocks = [4, 4, 4, 4]for i, num_convs in enumerate(num_convs_in_dense_blocks): net.add(DenseBlock(num_convs, growth_rate)) # 上一个稠密的输出通道数。 num_channels += num_convs * growth_rate # 在稠密块之间加入通道数减半的过渡块。 if i != len(num_convs_in_dense_blocks) - 1: net.add(transition_block(num_channels // 2))net.add(nn.BatchNorm(), nn.Activation('relu'), nn.GlobalAvgPool2D(), nn.Dense(10)) 不同于 ResNet 中将输入加在输出上完成跨层连接,DenseNet 在通道维上合并输入和输出来使得底部神经层能跟其上面所有层连接起来。
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
Lin, M., Chen, Q., & Yan, S. (2013). Network in network. arXiv preprint arXiv:1312.4400.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., & Anguelov, D. & Rabinovich, A.(2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
He, K., Zhang, X., Ren, S., & Sun, J. (2016, October). Identity mappings in deep residual networks. In European Conference on Computer Vision (pp. 630-645). Springer, Cham.
Huang, G., Liu, Z., Weinberger, K. Q., & van der Maaten, L. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (Vol. 1, No. 2).